以前の記事でも解説したように、CryptowatchのAPIから直接に取得できるBitflyerFXのローソク足は原則として最大6000件までです。
1)問題点
6000件のローソク足データは、1分足だと約4日分、1時間足でも8カ月分程度にしかなりません。より広範なバックテストをしたいとき(例えば、フォーワードテストやローリングウィンドウなどをしたい場合)は、少し物足りなく感じるでしょう。
また複数の時間軸を併用する売買ロジックをテストするときや、他の時間軸と成績を比較したいときに、期間が揃わないという問題もあります。そこで、自前でローソク足データを定期的に収集して保存するスクリプトを作成してみましょう。
※ 収集した価格データは個人利用の目的でのみ使用できます。
2)普通に価格を取得して保存するスクリプト
最終的には、自動的に価格データを収集し、新しく増えた価格データ(差分)だけを上書きで追加していくスクリプトを作ります。
まずは普通にCryptowatchのAPIで取得したJSONデータをそのままファイルに保存するコードを作成してみましょう。
pythonコード
import requests
from datetime import datetime
import time
import json
chart_sec = 60 # 保存したいローソク足の時間軸
file = "./test.json" # 保存するファイル名
# Cryptowatchのデータを単に保存するだけの関数
def accumulate_data(min, path, before=0, after=0):
# APIで価格データを取得
params = {"periods" : min }
if before != 0:
params["before"] = before
if after != 0:
params["after"] = after
response = requests.get("https://api.cryptowat.ch/markets/bitflyer/btcfxjpy/ohlc",params)
data = response.json()
#ファイルに書き込む
file = open( path,"w",encoding="utf-8")
json.dump(data,file)
return data
# メイン処理
accumulate_data(chart_sec, file ,after=1483228800)
ここまでは、以前に勉強した内容そのままです。
CryptowatchのAPIの基本的な仕様やパラメーターをよく理解していない方は、まず以下の記事を参考にしてください。
・バックテストに必要な過去の価格データを集めよう
これで、まずは上記のコードで直近6000件の価格データをファイルに保存することができました。試しにこちらのコードを1分足で実行してみましょう。
実行結果
▽以下のようにファイルに保存されます
▽ APIで取得する内容がそのまま保存されます
3)差分だけを取得して追加保存するスクリプト
では次に、さきほど作成したファイルに新しく増えた価格データ(差分)だけを追加取得するスクリプトを作ってみましょう。
仮にさきほどのファイルを file1、新しく保存するファイルを file2 とします。もちろん実際のスクリプト運用時には、両者は同じファイル名になります。
import requests
from datetime import datetime
from pprint import pprint
import time
import json
chart_sec = 60 # ローソク足の時間軸
file1 = "./test.json" # 読み込み元のファイル名
file2 = "./test2.json" # 追加保存するファイル名
# Cryptowatchから差分だけを追加して保存する関数
def accumulate_diff_data(min, read_path, save_path, before=0, after=0):
# APIで価格データを取得
params = {"periods" : min }
if before != 0:
params["before"] = before
if after != 0:
params["after"] = after
response = requests.get("https://api.cryptowat.ch/markets/bitflyer/btcfxjpy/ohlc",params)
web_data = response.json()
web_data_set = set( map( tuple, web_data["result"][str(min)] ))
# ファイルから価格データを取得
file = open( read_path,"r",encoding="utf-8")
file_data = json.load(file)
del file_data["result"][str(min)][-1] # 末尾は被るので削除
file_data_set = set( map( tuple, file_data["result"][str(min)] ))
# 差分を取得
diff_data_set = web_data_set - file_data_set
diff_data = list(diff_data_set)
# 差分を追加する
if len(diff_data) != 0:
print("{}件の追加データがありました".format( len(diff_data) ))
diff_data.sort( key=lambda x:x[0] )
file_data["result"][str(min)].extend( diff_data )
pprint(diff_data)
#ファイルに書き込む
file = open( save_path,"w",encoding="utf-8")
json.dump(file_data,file)
return file_data
# ---- ここからメイン ----
# 差分の価格データを保存する
accumulate_diff_data(chart_sec, file1, file2, after=1483228800)
1分足の価格データをCryptowatchのAPIで取得し、さらに同じ1分足の価格データをファイルから読み込み、差分を取得して、増えた価格データだけを配列の末尾に追加して再保存しています。
file1 と file2 に同じファイルを指定すると上書き保存になります。今回は、説明しやすいように敢えて別のファイル名にしています。
実行結果
試しに2時間後に上記のコードを同じ1分足で実行してみました。
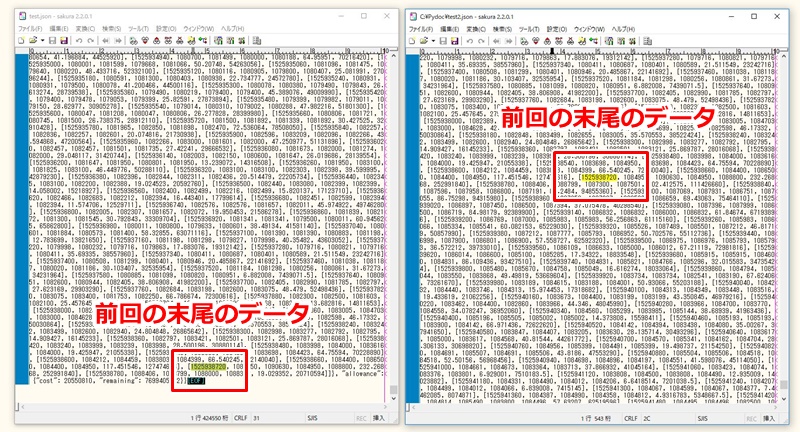
▽以下のようにファイルに保存されます
▽差分だけが順番通りに追加されています
コードの解説
pythonで配列同士の差分を取得したい場合には、集合型(set型)を使います。set()で、配列を集合に変換することができます。
差分をpythonで取得する方法
a = [1,2,3,4,5]
b = [3,4,5,6,7]
# 集合に変換
set_a = set(a)
set_b = set(b)
# 差分を取得
diff = set_b - set_a
# 結果:{6,7} を取得
# 配列に戻す
diff = list(diff)
# 結果:[6,7] を取得
このとき、引く順番に注意してください。
集合B に新しく増えたデータを取得したい場合には、(集合B – 集合A)を計算する必要があります。
今回の例でいえば、知りたいのは、(Cryptowath の価格データの集合) - (ローカルファイルの価格データの集合) です。
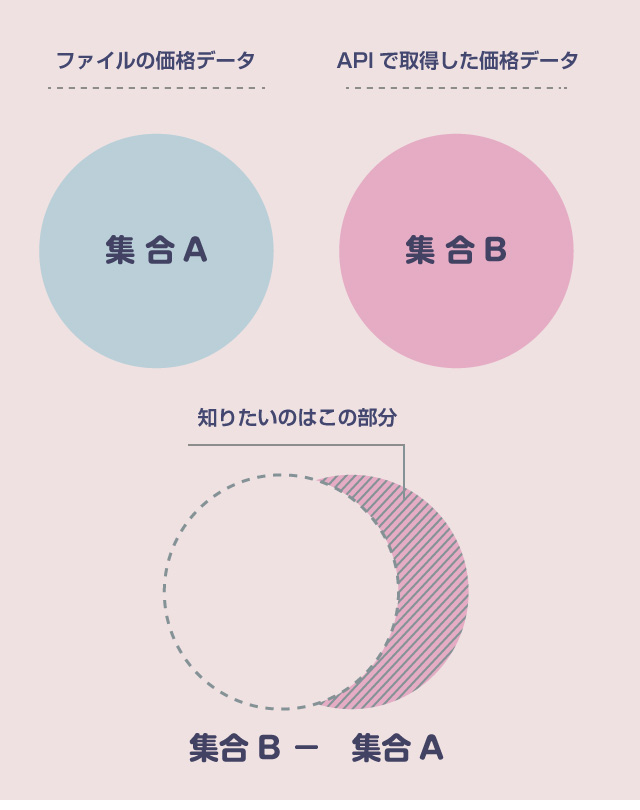
多次元配列を集合に変換する方法
ただしCryptowatchの価格データは、[ 日時, 始値, 高値, 安値, 終値,… ] の配列が、[[],[],[],[],[],[],[]… ] と何個も並んだ多次元配列の構造になっています。
多次元配列はそのままでは集合に変換できませんので、一度、タプル型に変換する必要があります。そのため、以下のように map( tuple,
配列 ) で囲っています。
web_data_set = set( map( tuple, web_data["result"][str(min)] ))
file_data_set = set( map( tuple, file_data["result"][str(min)] ))
これについては、以下の記事を参考にさせて貰いました。
・集合型で2次元リストの中の重複した行を削除する
差分データの順番を時系列順に直す
2つの集合の差分を取った時点では、新しく増えた差分の価格データは順番がぐちゃぐちゃです。そのため、これを時系列順に直してから元のファイルの配列の末尾にくっつけます。
多次元配列の順番は、以下のように修正できます。
# ぐちゃぐちゃの順番の多次元配列
number = [[ 12,314356 ],[ 13,351243 ],[ 15,334324 ],[ 11,304324 ],[ 10,313243 ],[ 14,332343 ]]
# 1番目を基準にソートしたい場合
number.sort( key=lambda x:x[0] )
# 実行結果
# [[10, 313243], [11, 304324], [12, 314356], [13, 351243], [14, 332343], [15, 334324]]
# 2番目を基準にソートしたい場合
number.sort( key=lambda x:x[1] )
# 実行結果
# [[11, 304324], [10, 313243], [12, 314356], [14, 332343], [15, 334324], [13, 351243]]
Cryptowatchの価格データは、配列の先頭の要素 [0] が日時データなので、こちらを基準にソートすればOKです。なお、pythonでの多次元配列のソートについては以下の記事が参考になります。
・参考:pythonでのソート
ファイルデータの末尾を削除する
Cryptowatchから取得した価格データの末尾には、まだ確定していないリアルタイムに形成中の足が含まれています。
こちらをそのまま放置すると、その時間の足が確定したときに「差分」として検出されてしまうため、出力後のファイルに同じ時間の足が2つ存在してしまうことになります。そのため、差分を取得する前にあらかじめ、元ファイルの末尾のデータを削除しておきます。
del file_data["result"][str(min)][-1] # 末尾は被るので削除
以上で完成です!
4)ファイルから価格データを読み込むスクリプト
最後にファイルから価格データを読み込むスクリプトを作っておきましょう。
今回の記事では、CryptowatchのAPIで取得したデータを加工せずにそのままJSON形式で保存しています。そのため、基本的にはCryptowatchのAPIをパースする関数を、そのまま流用することができます。
せっかくなので期間も指定できるようにしてみましょう。
import requests
from datetime import datetime
import time
import json
from pprint import pprint
chart_sec = 60 # ローソク足の時間軸
file = "./test2.json" # 読み込む価格ファイル
start_period = "2018/05/07 00:00"
end_period = "2018/05/08 00:00"
# 価格ファイルからローソク足データを読み込む関数
def get_price_from_file( min,path,start_period = None, end_period = None ):
file = open(path,"r",encoding="utf-8")
data = json.load(file)
start_unix = 0
end_unix = 9999999999
if start_period:
start_period = datetime.strptime(start_period,"%Y/%m/%d %H:%M")
start_unix = int(start_period.timestamp())
if end_period:
end_period = datetime.strptime( end_period,"%Y/%m/%d %H:%M")
end_unix = int(end_period.timestamp())
price = []
for i in data["result"][str(min)]:
if i[0] >= start_unix and i[0] <= end_unix:
if i[1] != 0 and i[2] != 0 and i[3] != 0 and i[4] != 0:
price.append({ "close_time" : i[0],
"close_time_dt" : datetime.fromtimestamp(i[0]).strftime('%Y/%m/%d %H:%M'),
"open_price" : i[1],
"high_price" : i[2],
"low_price" : i[3],
"close_price": i[4] })
return price
# ---- ここからメイン処理 ----
#ファイルから価格データを読み込む
price = get_price_from_file(chart_sec, file)
print("--------------------------")
print("テスト期間:")
print("開始時点 : " + str(price[0]["close_time_dt"]))
print("終了時点 : " + str(price[-1]["close_time_dt"]))
print(str(len(price)) + "件のローソク足データで検証")
print("--------------------------")
# 先頭50個だけプリントする
pprint( price[:50] )
仕様
最初に指定した期間をunix時間に変換して、開始時点(start_period)~終了時点(end_period)までのローソク足データを返します。
開始時点と終了時点を指定しなかった場合は、ファイルに存在する全てのローソク足を返します。また期間を指定した場合でも、その期間のデータが存在しない場合は、存在する範囲のローソク足データを返します。
では実行してみましょう!
実行結果
まずは以下のように何も引数を指定しなかった場合の実行結果です。
price = get_price_from_file(chart_sec, file)
▽ 実行結果
無事、6000件を超えるデータを取得できていますね。
では、次に期間を指定してみましょう。
期間を指定する場合は以下のように引数を設定します。
start_period = "2018/05/07 00:00"
end_period = "2018/05/08 00:00"
price = get_price_from_file(chart_sec, file, start_period, end_period)
▽ 実行結果
このように、指定期間のデータだけを抽出することができました!
5)データの欠損を調べる
ちなみに上記のデータには一部に欠損があります。
1分足で24時間の範囲を指定したのに、ローソク足データが1429件しかないのはおかしいですね。どのデータが欠損しているのか調べてみましょう。
さきほどのコードの末尾に以下のようなプログラムを足してみてください。
# どの時間のデータが抜けてるか調べる
num = int( datetime.strptime(start_period,"%Y/%m/%d %H:%M").timestamp() )
for i in range( len(price) ):
match = False
for p in price:
if num == p["close_time"]:
match = True
if match == False:
print("{} の価格データが存在しません".format(datetime.fromtimestamp(num)))
num += chart_sec
これを実行すると以下のようになります。
▽ 実行結果
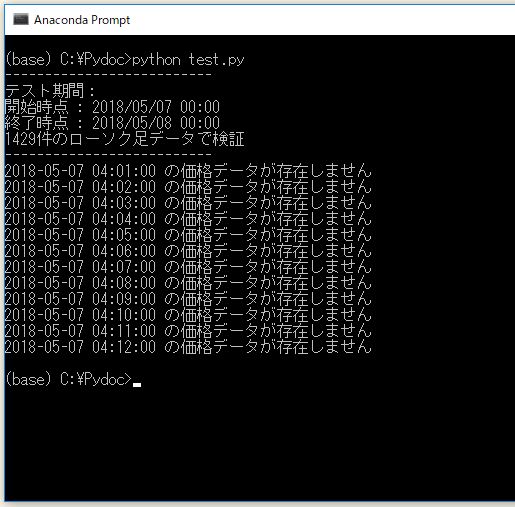
午前4時0分~12分までの1分足データがごっそり欠落しています。直接、ブラウザでAPIを叩いてみても該当する時間帯のローソク足のデータは存在しないことがわかります。
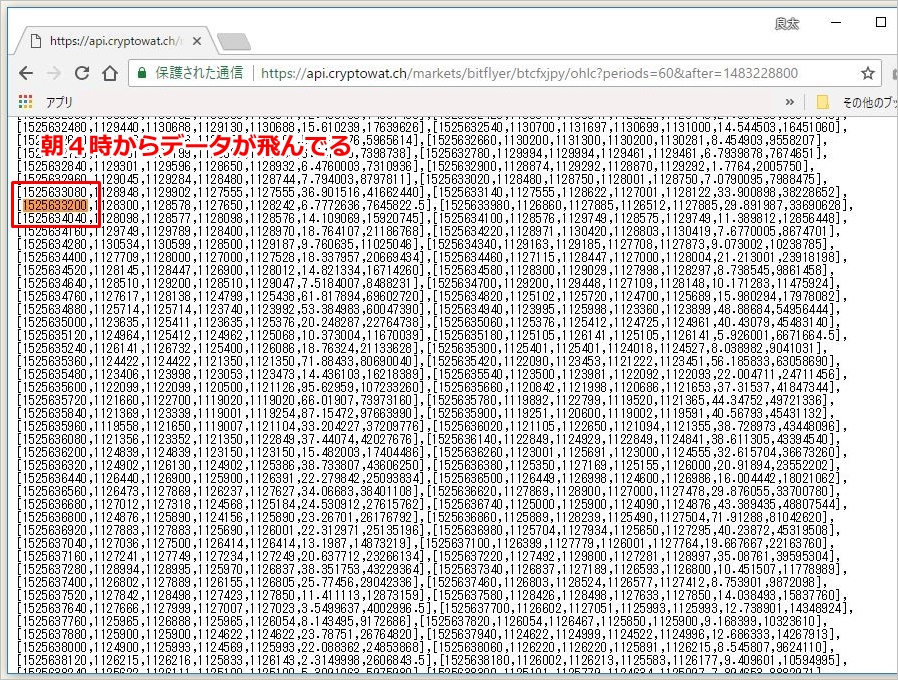
Bitflyerは毎朝4時にサーバーの定期メンテナンスがあります。そのため、他の日時で試しても、朝4時0分~10分頃のデータが存在しないことが多いようです。
それ以外にデータの欠損はありませんが、一応、ときどきこのようなデータの欠損がないかは確認してみるといいかもしれません。
6)データ収集の頻度
上記のコードの実行は、蓄積したいのが1時間足であれば1カ月に1度程度、1分足でも1~2日に1回実行すれば十分です。実行頻度がそれほど高くないため、常時起動してWhile文でループするのはあまりに効率が悪いです。
もちろん手動で実行しても構わないのですが、手動での実行だと忘れてしまう可能性もあります。そこで、Windowsのタスクスケジューラにpythonのファイルを登録して、OSに定期実行して貰うよう設定するのがお勧めです。
次の記事では、その具体的な方法を解説します!
参考:Windowsのタスクスケジューラでpythonを定期実行する