BOTの運用を成行注文で行っている場合、バックテスト上の成績と実際の成績が乖離する原因の1つにスリッページがあります。
成行注文や逆指値注文は、必ずしも理想の価格で約定するわけではありません。例えば、バックテスト上では「100万円で買いエントリーして98万円で損切りした」はずでも、成行注文が1%不利な価格で約定した場合、実際の運用は「101万円で買って97万円で売却する」ことになります。

この場合、1回の取引の損失は-2%(バックテスト)から-約4%(実際の運用)まで悪化します。
実際にどのくらいのスリッページが発生するかは、おそらく売買ロジックやボラティリティ、成行注文の数量によって異なるので、一概に何%と言うことはできません。この記事では、測定方法などを解説しますが、実際の数値は参考程度にしてください。
スリッページの計算方法
実際のスリッページの影響は、自分のロジックでBOTを一定の期間や回数動かしてみて、シグナル価格と約定価格の乖離を記録するしかないと思います。
例えば、以下は実際にログから過去300回程度の取引を抽出して、シグナル価格と約定価格の乖離をまとめたものの一部です。こちらの記事の方法を参考に、普段からBOTでシグナル価格や約定価格をログファイルに出力しておけば、簡単に集計できます。
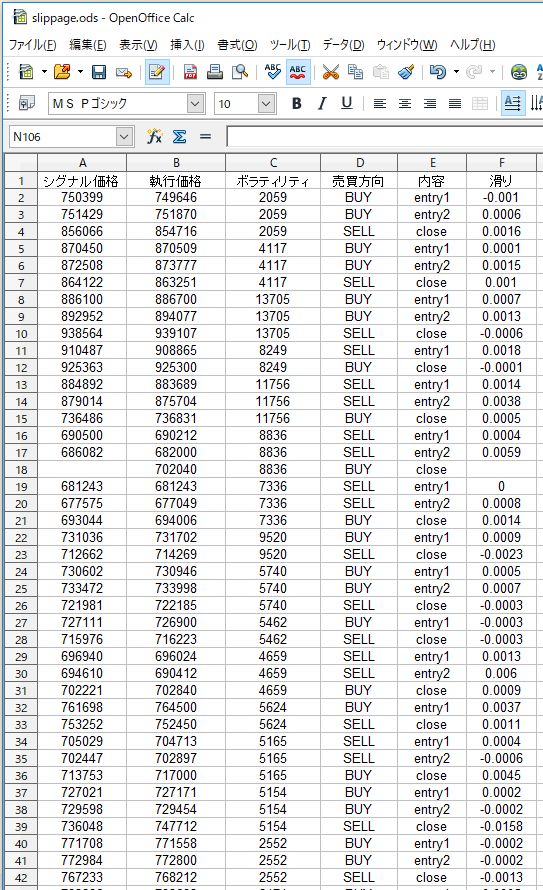
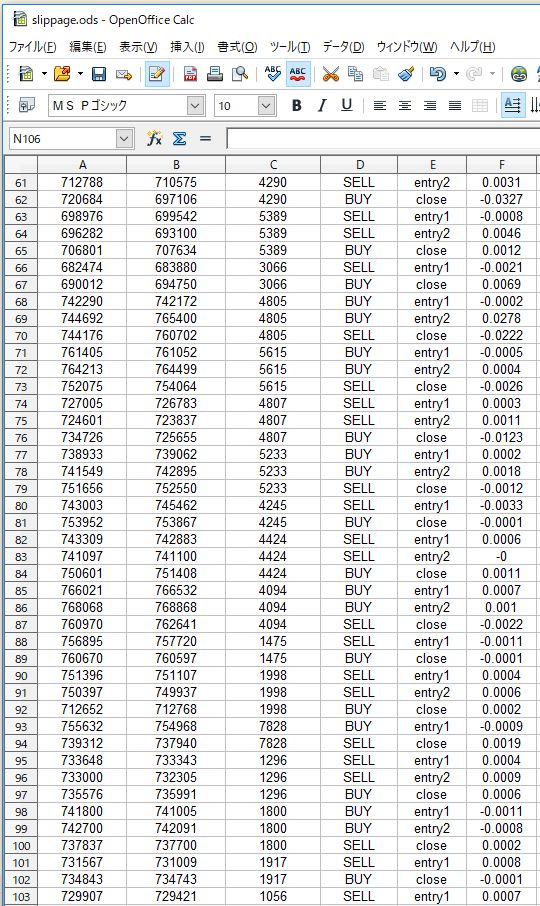
「滑り」の欄でプラスの数値になっているのは、想定していた価格よりも不利な価格で約定したときの乖離率(スリッページ)です。マイナスの数値になっているものは、想定していた価格よりも有利な価格で約定したときの乖離率です。
売買ロジックにもよると思いますが、実際に集計してみると「予想よりも有利な価格」で約定するケースも結構あります。後ほど、このヒストグラムを紹介します。
1)スリッページの計算式
この記事では、スリッページの定義を「シグナル価格に対して何%不利な価格で約定したか?」のコストを表す数値とします。そのままバックテストで使えるようにするためです。
計算式は以下になります。

スリッページの計算式では、注文がエントリーなのか手仕舞いなのかを区別する必要はありません。買い注文は想定より高く約定したら不利で、売り注文は想定より安く約定したら不利です。このことは常に成り立ちます。
2)ログから欲しい数値を集計する方法
ログなどのテキストファイルから、欲しい数値(ここではシグナル価格と約定価格)を抜き出す方法を紹介します。どのようなログを出力するかは人によって違うので、ここでは具体的なコードというより、考え方だけ紹介しておきます。
▽ 例)ログのフォーマット
時間: 2019/04/26 06:00 高値: 622124 安値: 618640 終値: 622000
時間: 2019/04/26 07:00 高値: 622423 安値: 609400 終値: 610253
時間: 2019/04/26 08:00 高値: 610597 安値: 555556 終値: 580936
過去**足の最安値609350円を、直近の価格が580936円でブレイクしました
現在のアカウント残高は**円です
現在の**期間の平均ボラティリティは**円です
許容リスクから購入できる枚数は最大**BTCまでです
**回に分けて**BTCずつ注文します
580936円あたりに**BTCの売りの成行注文を出します
--------------------
{'info': {'child_order_acceptance_id':***}
--------------------
すべての成行注文が執行されました
執行価格は平均 579700円です
このテキストから抽出したい情報を以下の2つとします。
1)シグナル価格(バックテスト上で用いている価格) 580936円
2)実際の約定価格 579700円
3)スリッページ(乖離率) +0.21%
これを抽出するには、正規表現 というものを使うと便利です。例えば、以下のようなコードを作成すれば、ログファイルを1行ずつ読み込んで、欲しい数字だけを抽出することができます。
▽ コードの例
# 正規表現を扱うライブラリ
import re
# テキストファイルを読み込む
f = open("./logfile.txt", "r", encoding="UTF-8")
line = f.readline()
# 抽出したい情報
signal_price = []
execution_price = []
# 1行ずつ読み込んで処理
while line:
line = f.readline()
if "ブレイクしました" in line:
price = re.match(".*価格が?(\d+)円でブレイクしました", line).group(1)
price = int(price) # 数値にする
signal_price.append( price )
if "執行価格は" in line:
price = re.match(".*執行価格は.*?(\d+)円です", line).group(1)
price = int(price)
execution_price.append( price )
f.close()
print(signal_price)
print(execution_price)
re.match() の関数の箇所が「正規表現」です。
正規表現とは、毎回、出現する文字や数字の内容が違っている場合でも、その出現パターンさえ同じであれば、()で括られた箇所だけを抜き出すことができる便利な記述ルールです。以下の記事で、詳しい正規表現のルールが記述されているので参考にしてください。
実際のログファイルには、BOTの停止や手動での決済が混じってる場合も多く、欲しい情報を正しくセットで抜き出すためには、もう少し複雑なコードを考える必要があります。が、基本的には上記の方法の組み合わせで実現できます。
欲しい数字を全て抽出したら、以前の記事で紹介したようにpandasでデータフレームに変換して、csvなどの形式で出力すれば準備完了です。
3)スリッページの集計
全ての取引のスリッページ(シグナル価格と約定価格との乖離率)をcsvにまとめることができたら、次にそれを分析してみましょう。
今回は以下のような分析結果を作る方法を紹介します。
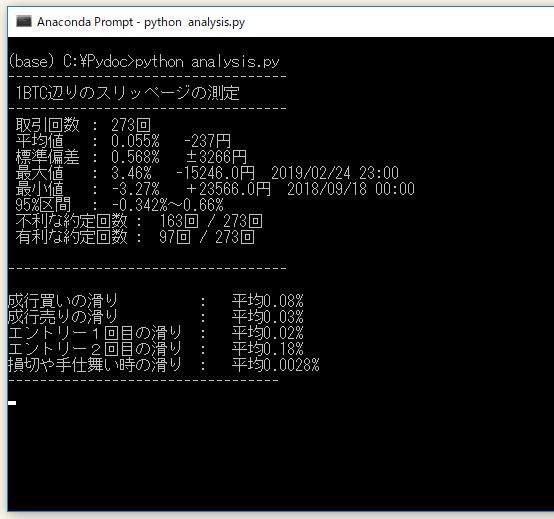
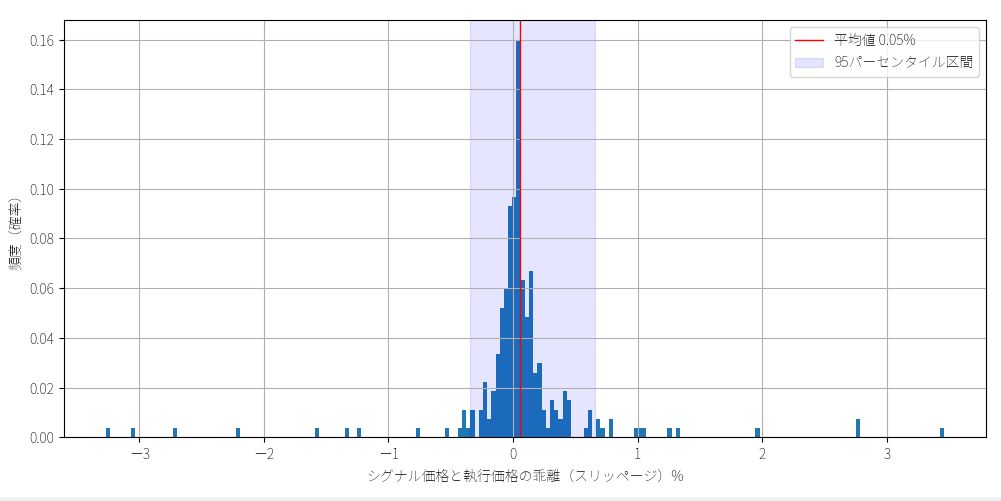
私の運用BOTの場合は上記のような集計結果になりました。
全取引のうち、およそ6割が不利な価格で約定し、約3割が有利な価格で約定しています。また順張りのロジックのため、明らかにエントリー時に偏って約定価格の滑りが発生しています。複数回に分けてエントリーする場合、後半になるほどバックテストで想定するより不利な価格で約定しています。一方、損切りや利確時にはほとんど滑りは発生していませんでした。
また全取引のうち95%は-0.3%~0.6%の乖離で約定していて、平均としては 0.1%程度の滑りを考慮すれば足りそうだとわかりました。たまに±3%前後で大きく滑っていますが、異常値は必ずしも不利な方向に発生するわけではないようです。
4)集計コードの作り方
最初に示したようなフォーマットのcsvファイルを無事に作成できたと仮定して、話を進めましょう。
具体的な分析のコードが以下です。
▽ 分析用のコード
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import csv
#------------------------------------
import matplotlib as mpl
font = {"family":"Noto Sans CJK JP"}
mpl.rc("font",**font)
#-------------------------------------
# 集計データを読み込み
data = pd.read_csv("./data.csv", encoding="UTF-8", sep=",")
# 全取引の95%が収まる範囲を計算
percentile_5 = round( np.percentile( data["滑り"].dropna(),5 ) *100,3) # 下位5%
percentile_95 = round( np.percentile( data["滑り"].dropna(),95) *100,3) # 上位5%
print("-----------------------------------")
print(" 1BTC辺りのスリッページの測定")
print("-----------------------------------")
print(" 取引回数 : {}回".format( len(data["滑り"]) ))
print(" 平均値 : {}%".format( round(data["滑り"].mean() * 100,3) ))
print(" 標準偏差 : {}%".format( round(data["滑り"].std() * 100,3 ) ))
print(" 最大値 : {}%".format( data["滑り"].max() * 100 ))
print(" 最小値 : {}%".format( data["滑り"].min() * 100 ))
print(" 95%区間 : {}%~{}%".format( percentile_5, percentile_95 ))
print(" 不利な約定回数 : {}回 / {}回".format( len( data[ data["滑り"]>0 ]), len(data) ))
print(" 有利な約定回数 : {}回 / {}回".format( len( data[ data["滑り"]<0 ]), len(data) ))
print("")
print("-----------------------------------")
print("")
print("成行買いの滑り : 平均{}%".format( round( data[ data["売買方向"] == "BUY" ]["滑り"].mean(),4) * 100 ))
print("成行売りの滑り : 平均{}%".format( round( data[ data["売買方向"] == "SELL" ]["滑り"].mean(),4) * 100 ))
print("エントリー1回目の滑り : 平均{}%".format( round( data[ data["内容"] == "entry1" ]["滑り"].mean(),4) * 100 ))
print("エントリー2回目の滑り : 平均{}%".format( round( data[ data["内容"] == "entry2" ]["滑り"].mean(),4) * 100 ))
print("損切や手仕舞い時の滑り : 平均{}%".format( round( data[ data["内容"] == "close" ]["滑り"].mean(),6) * 100 ))
#print("ボラティリティとの相関係数 : {}".format( data["滑り"].corr( data["ボラティリティ"] ) ))
print("----------------------------------")
#------------------------------------------
# グラフの描画
#------------------------------------------
n1, n2 = np.histogram( data["滑り"].dropna()*100, bins=200 )
# numpy の histogram() を使って n1(binの境界)とn2(度数)を取得する
# dropna() は空白行を落とすために使用
# ヒストグラムを表示
y = n1/float(n1.sum()) # 頻度(度数)をもとに確率を計算する(縦軸)
x = (n2[1:] + n2[:-1])/2 # 境界[0番目,1番目,2番目,...5番目]と[1番目,2番目,3番目,...6番目]からbinの中央値を計算(横軸)
x_width = n2[1] - n2[0] # binの幅を取得
plt.bar( x, y, width=x_width ) # 棒グラフの描画
# 平均値をグラフに表示
plt.axvline( data["滑り"].mean()*100, color="red",linewidth=1, label="平均値 {}%".format( round(data["滑り"].mean()*100,2 ) ))
# 95パーセンタイル区間を塗りつぶし
plt.axvspan( percentile_5, percentile_95, color="blue",alpha=0.1, label="95パーセンタイル区間")
plt.grid(True)
plt.xlabel("シグナル価格と執行価格の乖離(スリッページ)%")
plt.ylabel("頻度(確率)")
plt.legend()
plt.show()
csvファイルを読み込んで、pandasを使って集計しています。
pandasの使い方はこちらの記事で解説しているので参考にしてください。
またmatplotlibのhist()関数では、縦軸の目盛りを確率にすることが難しいようだったので、numpyでヒストグラムにしました。
スリッページの影響
スリッページコストが最終的な成績にどの程度の影響を及ぼすかは、BOTの売買頻度によって異なります。
期待リターン2%の取引を年間200回するBOTと、期待リターン0.2%の取引を年間2000回するBOTでは、理論上の期待リターンは同じです。しかしここに0.1%のスリッページコストを考慮すると、前者の利回りは年間380%である一方、後者は期待リターンが100%になり、最終成績は4倍近い差となります。