前回の記事では、ドンチャンブレイクアウトの自動売買BOTの成績を、matplotlibを使って視覚的なグラフにする方法や、最大ドローダウンを計算する方法を説明しました。
しかし自動売買BOTの安定性を評価するためには、最終的な損益だけでなく途中の経過、つまり月別の成績を把握しておくことも必須です。
今回の記事では、これらの成績(平均リターン・ドローダウン・勝率など)を月別に集計する方法を解説します!
Pandasを使ってデータを集計しよう!
前回までのやり方の問題点
前回までの記事では、なるべくpythonのプログラミング初心者でもわかりやすいように、すべてのトレード成績を配列に記録していました。
flag変数に以下のような配列を用意して、ポジションを手仕舞うたびに各トレードの成績や指標を計算し、各配列に append していましたよね。
flag = {
"records":{
"buy-count": 0,
"buy-winning" : 0,
"buy-return":[],
"buy-profit": [],
"buy-holding-periods":[],
"sell-count": 0,
"sell-winning" : 0,
"sell-return":[],
"sell-profit":[],
"sell-holding-periods":[],
"drawdown": 0,
"date":[],
"gross-profit":[0],
"slippage":[],
"log":[]
}
}
しかしこのやり方だと、買いエントリーと売りエントリーに分けて成績を記録しているため、違う切り口でデータを集計したいときに凄く不便です。
例えば、「売り・買いで分けずに、月別の平均リターンや勝率を検証したい」と思った場合、売り・買いそれぞれのデータを(順番がおかしくならないように)くっつけて、それを日付で分割する、というややこしい処理をしなければなりません。
新しく月別の勝率を記録する変数を用意する方法もありますが、そうするとflag変数がどんどん増えていってしまい、pythonコードがどんどん長くややこしくなります。
もっとシンプルにデータを記録しておいて、あとから欲しい数字だけを上手に集計する方法はないでしょうか?
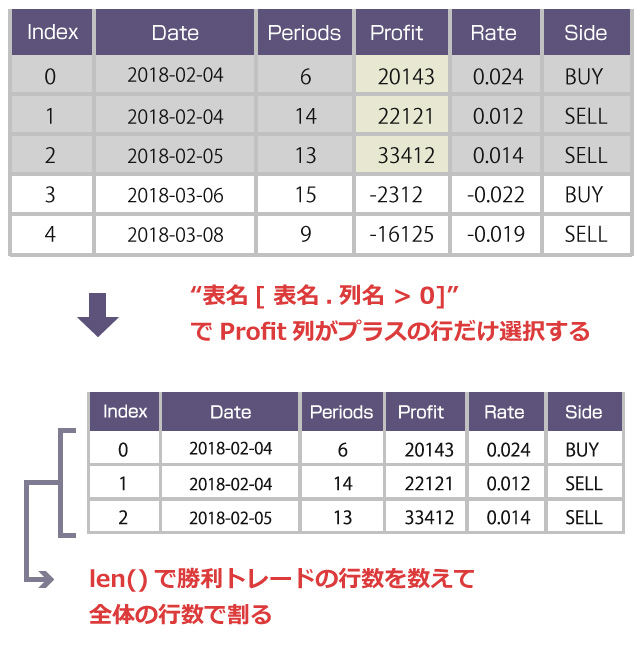
表のような形式で成績を記録する
もし以下のような表形式で各トレードの成績を記録しておけば、どうでしょうか? Excelのシートのようなイメージですね。
| 日付 | 損益 | 方向 | 保有期間 |
|---|---|---|---|
| 2018-02-04 | 20143円 | 買いエントリ | 6足分 |
| 2018-02-04 | 22121円 | 売りエントリ | 14足分 |
| 2018-02-05 | 33412円 | 売りエントリ | 13足分 |
| 2018-03-06 | -2312円 | 買いエントリ | 15足分 |
| 2018-03-08 | -16125円 | 売りエントリ | 9足分 |
もし、このような表データを1つの変数として保持することができ、後から以下のような計算ができれば便利です。
————————————————————–
例)
・B列の「損益」のうちC列が「買い」のものだけを合計する
・A列の日付が2018-02のものだけで、B列の「損益」の平均値を求める
・後からE列を追加してそこに左列の損益の合計値(累積和)を追加する
・B列の「損益」のうち値がプラスのもの(=勝ち数)だけをカウントする
————————————————————–
このようなことは、Excelシートだと簡単にできますよね。同じことがpythonでも出来ないでしょうか?
実は、全く同じようなことがpythonでできるライブラリがあります。それがPandasデータフレームです。
Pandasは表計算ソフトのようなもの
Pythonを勉強しはじめた初心者の方でも、「Pandas」という言葉を聞いたことがあるかもしれません。「なんだか上級者向きの難しい奴でしょ?」というイメージをお持ちの方も多いかもしれません。
しかしPandasは全く難しくありません。要するに「Excelのような表計算ソフトと同じようなものだ」と思えば、文系の方でも少し親近感が湧きますよね。
この記事では、バックテストのデータ集計に必要なpandasの使い方を、1回でほぼ全て習得することを目指します! ぜひ今回の記事でpandasの使い方をマスターしてしまいましょう!
Pandasの使い方をマスターする
1)まずは表型のデータを作ってみよう!
pandasでは、複数行・複数列にわたる表形式のデータのことを「DataFrame」といいます。まずは練習としてDataFrame型の変数を1つ作ってみましょう!
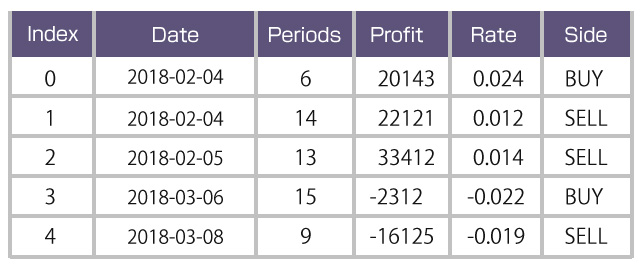
今回は、以下のような5回分のトレード成績を記録した配列を用意しました。これは先ほど表の例と全く同じものです。今回はこちらを例に説明していきます。
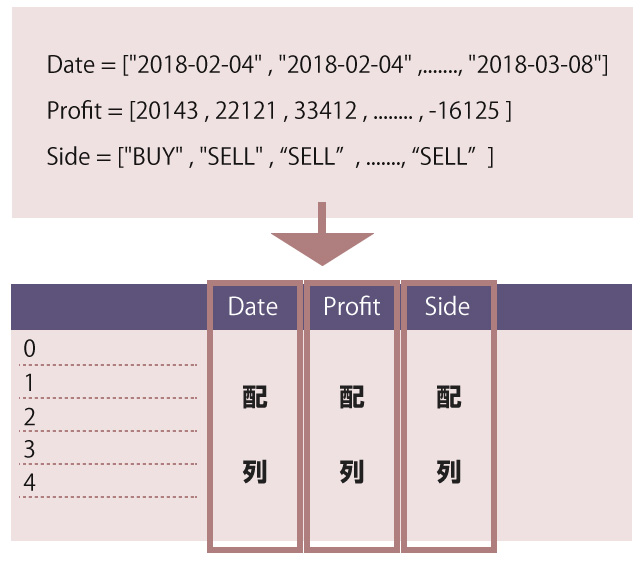
# 今回の練習で使う5回分のトレード成績のサンプル Date = ["2018-02-04","2018-02-04","2018-02-05","2018-03-06","2018-03-08"] Profit = [20143,22121,33412,-2312,-16125] Side = ["BUY","SELL","SELL","BUY","SELL"] Rate = [0.024,0.012,0.014,-0.022,-0.019] Periods = [6,14,13,15,9]
まずは上記のように、「日付」「各トレードの損益」「エントリーの方向」「保有期間」など、表を作るために必要な最低限の情報を記録した配列を用意します。
「トレード回数」「ドローダウン」「総損益」「買いエントリーの勝率」など、後から表をもとに計算できる数字は、この時点で準備する必要はありません。つまりトレードするたびに記録する数字は、上記の5種類だけでOKということです。
すべてのトレードが終わったら、上記の配列をくっつけて1つのDataFrame型の表データに変換します。それが以下のコードです。
import pandas as pd
# 上の配列データをくっつけて1つの表データにする
records = pd.DataFrame({
"Date":pd.to_datetime(Date), # 文字を日付型に変換
"Profit":Profit,
"Side":Side,
"Rate":Rate,
"Periods":Periods
})
各配列を縦向きの「列」として結合し、1つのDataFrame型の表にして records という名前の変数に入れています。
これを公式にすると、以下のような感じですね。
表型の変数名 = pd.DataFrame({
"列名" : データ配列 ,
"列名" : データ配列 ,
"列名" : データ配列 ,
"列名" : データ配列
})
日付データだけは、pd.to_datetime()を使って、テキスト型から日付型に変換しておきます。その理由は、前回の記事で解説しています。
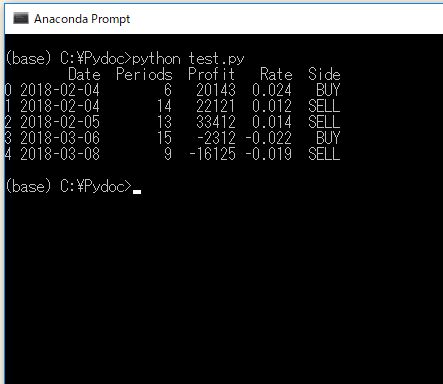
さて、これで先ほどイメージした表データをpythonで作ることができました! 念のためにprintしてみましょう!
print( records )
以下のようになります。
▽ 上記のコードで作った配列データ
▽ 今回の練習で使う表
欲しい数字だけを集計して取り出そう!
では、次にこの表データ(records)から「欲しい数字」を取り出していきましょう。 以下、よく使うパターンをまとめて列挙していきます。
1.損益データだけを取り出す
print( records.Profit )
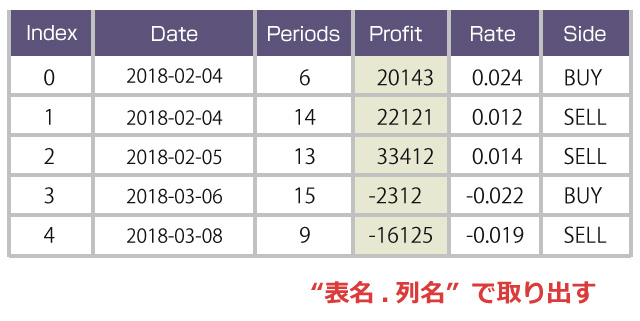
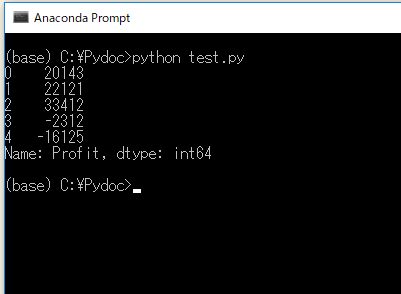
列名が英文字の場合は、records.profit のように「表名.列名」指定できます。 列名が日本語の場合は、records[“損益”] のように指定します。
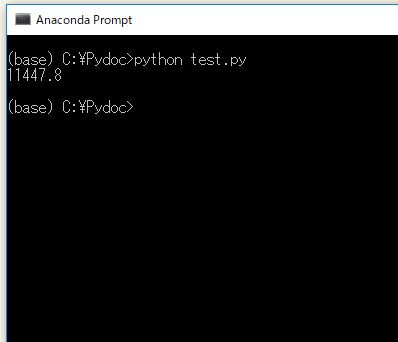
2.平均リターンを計算する
print( records.Profit.mean() )
3.損益の合計を計算する
print( records.Profit.sum() )
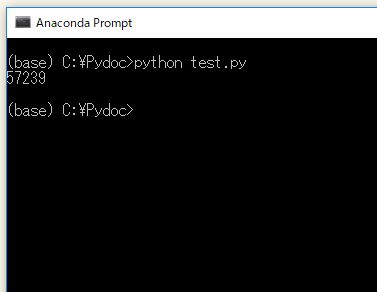
3.特定の行のデータを取り出す
print( records.iloc[2] )
![表名.iloc[2]で2行目だけを取り出す](https://ryota-trade.com/wp-content/uploads/2018/04/pandas_5.jpg)
locは、loc[ 行名, 列名 ] のかたちで表データの範囲を指定する記述方法です。一方、ilocは、iloc[ 行番号, 列番号 ]のかたちで表データ範囲を指定する記述方法です。
これらは以下のサイトに詳しい説明があります。
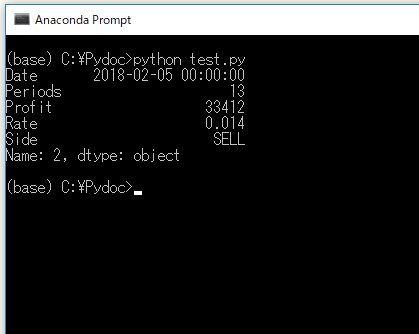
4.買いエントリーのデータを取り出す
print( records[records.Side.isin(["BUY"])] )
![表名[ 表名.列名.isin([値]) ]でSide列が”BUY”の行だけ取り出す](https://ryota-trade.com/wp-content/uploads/2018/04/pandas_6.jpg)
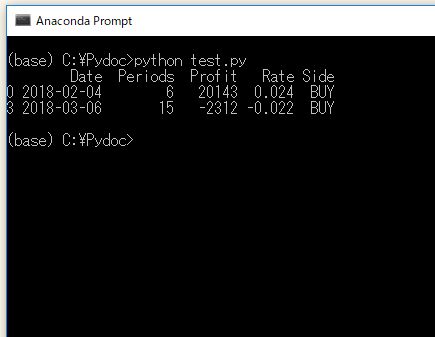
5.買いエントリーの損益だけを取り出す
print( records[records.Side.isin(["BUY"])].Profit )
![表名[ 表名.列名.isin([値]) ].列名でSide列が”BUY”の行のProfit列を取り出す](https://ryota-trade.com/wp-content/uploads/2018/04/pandas_7.jpg)
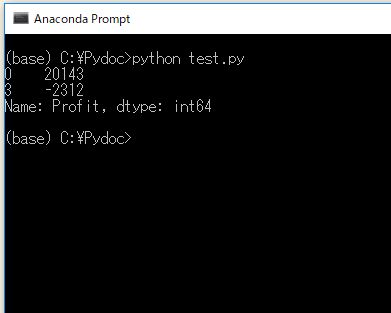
6.買いエントリーの平均リターンを計算する
print( records[records.Side.isin(["BUY"])].Profit.mean() )
![表名[ 表名.列名.isin([値]) ].mean() でSide列が BUYの行のProfit列の平均値を計算する](https://ryota-trade.com/wp-content/uploads/2018/04/pandas_8.jpg)
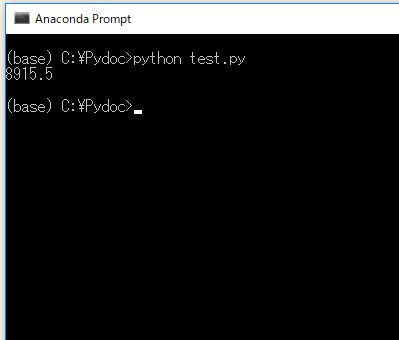
7.トレード回数をカウントする
# 全トレード数をカウントする print( len(records) ) # 買いエントリーのトレード数をカウントする print( len( records[records.Side.isin(["BUY"])] ))
![len(表名) で行数を数える / len(表名[ 表名.列名.isin([値]) ])でSide列が BUYの行の行数を数える](https://ryota-trade.com/wp-content/uploads/2018/04/pandas_9.jpg)
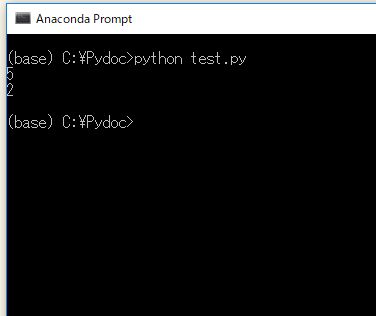
len( 表名 )のかわりに、表名.列名.count() と書いても構いません。
8.勝率を計算する
# 全体の勝ちトレードの数をカウントする print( len(records[records.Profit > 0]) ) # 全体の勝率を計算する print( len(records[records.Profit > 0]) / len(records) * 100 )
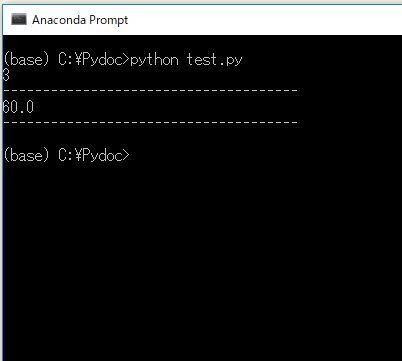
勝率は、勝ちトレード数 / 全体のトレード数 で計算できます。そのため、Profit列が0以上の行の数を数えて、それを全体の行数で割れば、全体の勝率が計算できます。
# 買いエントリーの勝ちトレードだけを取り出す print( records[records.Side.isin(["BUY"]) & records.Profit>0] ) # 買いエントリーの勝ちトレード数をカウントする print( len(records[records.Side.isin(["BUY"]) & records.Profit>0]) ) # 買いエントリーの勝率を計算する print( len(records[records.Side.isin(["BUY"]) & records.Profit>0]) / len(records.Side.isin(["BUY"])) * 100 )
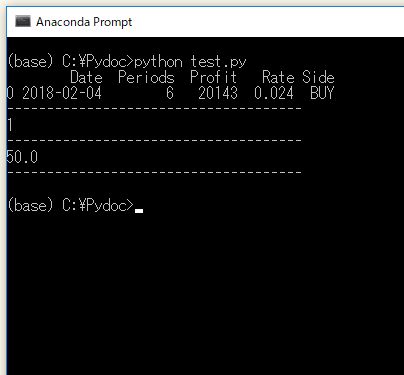
同じことを、Side列が BUY の行だけに限定して行えば、買いトレードの勝率を計算できます。
9.各日付時点での総損益を新しい列に追加する
records["Gross"] = records.Profit.cumsum()
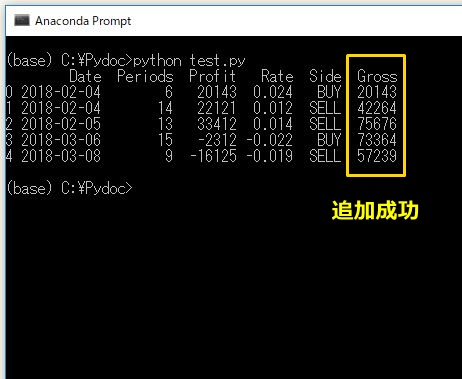
後から新しい列を追加したいときは、records[“新しい列名”] = 式 と書くことで新しい列を作成できます。また総損益とは、要するに利益の累積和のことなので、Profit列のcumsum()を計算します。
10.各日付時点のドローダウンを新しい列に追加する
records["Drawdown"] = records.Gross.cummax().subtract( records.Gross )
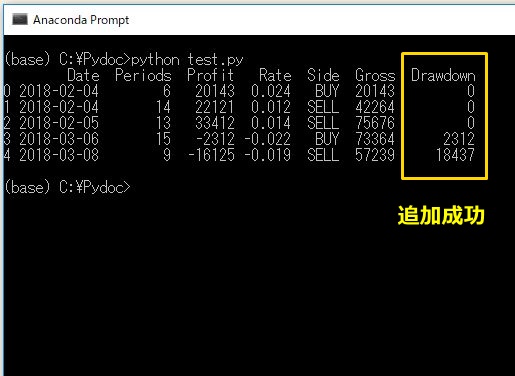
cummax()で累積最大値を調べることができます。累積最大値とはその行までの最大値のことです。例えば、Gross列の2行目までの累積最大値は42264、3行目までの累積最大値は75676になります。
最大ドローダウンとは、要するに「 n行目までの総利益の累積最大値から n行目の総利益を差し引いたもの」なので、上記の式で各行の最大ドローダウンを計算できます。引き算には、subtract()を使います。
終了
はい!
ここまでで、今までの記事で勉強してきたバックテストの成績の指標は、すべてpandasに置き換えることができました! 何となくpandasの便利さを実感できたのではないでしょうか?
月別にバックテスト結果を集計しよう!
pandasではさらにグルーピングという便利な機能があります。上記で作成した表データを、月ごとにグルーピングしてみましょう!
以下のように書くだけです。
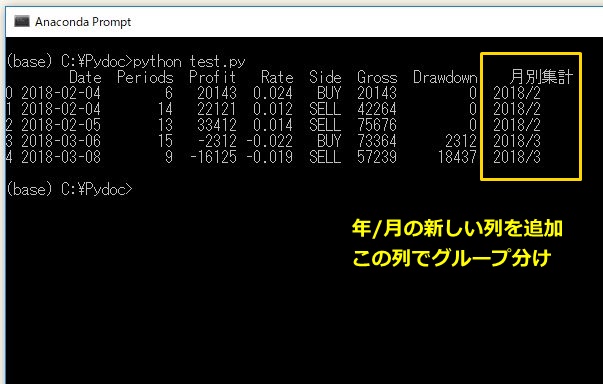
records["月別集計"] = records.Date.apply(lambda x: x.strftime('%Y/%m'))
grouped = records.groupby("月別集計")
month_records = pd.DataFrame({
"Gross" : grouped.Profit.sum(),
"Rate" : round(grouped.Rate.mean()*100,1),
"Drawdown" : grouped.Drawdown.max(),
"Periods" : grouped.Periods.mean()
})
print("---------------------------------------------------")
print( month_records )
groupby()でグループ分けできる!
groupby( 列名 )で特定の列を指定すると、その列の値が同じもの同士をグループ化することができます。例えば、groupby(“Side”)でグループ分けすれば、買いエントリーと売りエントリーとでデータをグループ分けできます。
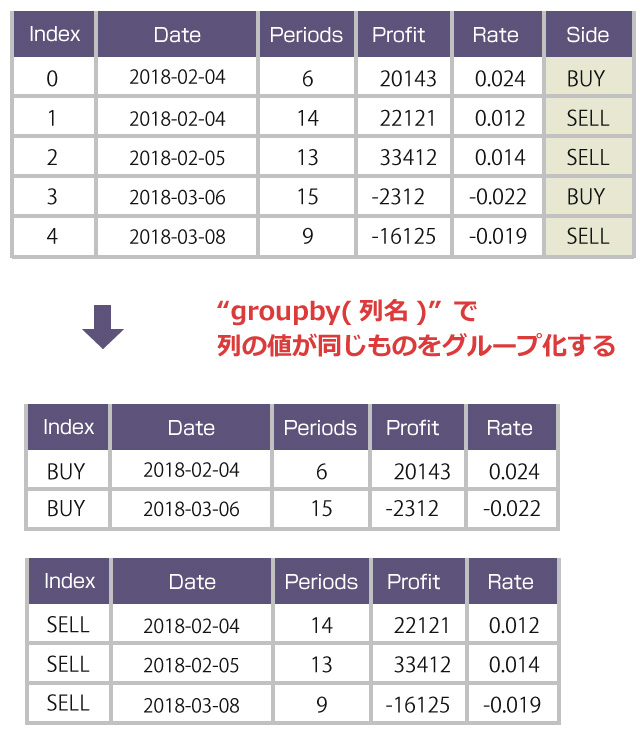
ここでは「月別」にデータをグループ分けします。ただし2017年3月と2018年3月が、同じ「3月」でグルーピングされると困りますよね。「〇年〇月」までをセットでグルーピングしなければなりません。
そのため、最初に以下の1行を書いています。
records["月別集計"] = records.Date.apply(lambda x: x.strftime('%Y/%m'))
ここでは、グループ分けをするために専用の新しい列を作っています。
もともと存在したDate列のデータを「年/月」のかたちに変形し、それを新しく作った「月別集計」という列に入れる、という処理をしています。
補足)lambda と apply() で全行のデータを変形する
ここには、apply()とlambdaという新しい記述方法が登場しています。
lambda は「 lambda 変数 : 式 」と書いて、変数を式のかたちに変形する記述方法です。表データに対して、apply( lambda 引数 : 式 ) と記述することで、表データのすべての行に対して、まとめて同じ式の処理を実行することができます。
以下の例をみるとわかりやすいでしょう。
(例)
number = pd.DataFrame({"data":[10,20,30,40,50]})
number = number.apply(lambda x : x+5)
# これを実行するとデータは{ "data":[15,25,35,45,55] } になります。
for文のような処理を、表(DataFrame型)に適用するための記述方法ですね。もっと興味がある方は、apply()やlambdaを調べて勉強してみてください。
さて、これで「年/月」という新しい列ができたので、この列を基準にグループ分けをします。それが以下の行です。
# グループ化する処理
grouped = records.groupby("月別集計")
この1行だけで、「月別集計」の列が同じもの同士をグループ化することができます。
グループ化したデータの使い方
グループ化したデータの結果は、以下のようなかたちで取り出すことができます。
# グループ化したデータから値を取り出す grouped.Profit.sum() # グループごとのProfit列の合計値の配列を返す grouped.Profit.mean() # グループごとのProfit列の平均値の配列を返す grouped.Profit.max() # グループごとのProfit列の最大値の配列を返す
上記の結果を実行すれば、例えば、「2018/2」「2018/3」「2018/4」などのグループの、それぞれの利益の合計値、平均値、最大値を取り出すことができます。
月別のデータ集計といっても、欲しい数字は項目によって異なります。例えば、総損益なら合計値(sum)が必要ですし、平均リターンなら平均値(mean)が必要です。最大ドローダウンであれば最大値(max)が必要でしょう。
さて、それぞれ必要なデータを取り出したら、それを「列」として結合して新しい表(DataFrame)を作ります。配列データをくっつけて1つの表データにする方法は、1番最初に勉強しました。覚えていますよね?
month_records = pd.DataFrame({
"Gross" : grouped.Profit.sum(),
"Rate" : round(grouped.Rate.mean()*100,1),
"Drawdown" : grouped.Drawdown.max(),
"Periods" : grouped.Periods.mean()
})
print("---------------------------------------------------")
print( month_records )
これを実行すると以下のようになります。
実行結果
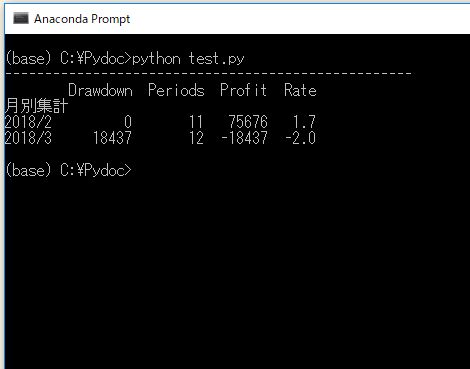
これで最初の5回分のトレード成績を、以下のように月別にグルーピングできました。
| 月別集計 | 最大ドローダウン | 平均リターン | 月間損益 | 平均保有期間 |
|---|---|---|---|---|
| 2018/2 | 0円 | 1.7% | 75676円 | 11期間 |
| 2018/3 | -18437円 | -2.0% | -18437円 | 12期間 |
練習問題
ドンチャン・ブレイクアウトBOTの月別リターンを集計しよう!
では、最後にここまで勉強したpandasの知識を使って、前回までの記事で作成した「ドンチャンブレイクアウトBOT」のバックテストのコードを改良しましょう!
以下のように月別の成績を集計して表示できるようにします! 具体的なコードは以下の記事に記載していますが、まずはご自身で挑戦してみてください。

こんにちは、いつも参考にさせていただいております。
この部分ですが、
# 買いエントリーの勝率を計算する
print( len(records[records.Side.isin([“BUY”]) & records.Profit>0]) / len(records.Side.isin([“BUY”])) * 100 )
おそらく、買いエントリーの総数を出すにはさらにrecords[]が必要だと思います。間違っていたら申し訳ないです
print( len(records[records.Side.isin([“BUY”]) & records.Profit>0]) / len(records[records.Side.isin([“BUY”]))] * 100 )